
Atany company, one of the best ways to gain and retain customers is to deliver excellent services, meaning the service should be healthy and functional whenever the customers access it. To achieve this, the tech industry introduced on-call duty which was often associated with doctors in the past.
The definition of on-call varies among companies. But here is the general description: Being on-call means being available and ready to respond to production incidents with appropriate urgency during a certain period of time. On-call is often associated with Software Engineers and Site Reliability Engineers (SRE) to support software such as APIs, websites, mobile apps, IoT services and etc.
Data engineers, on the other hand, seem to be not engaged with on-call duty as much as their peers. I will explain the reasons in a second. But this is going to change.
As someone who is interested in multidisciplinary, I want to share how we can set up an on-call culture in a data engineering team. Most of the experiences come from my current team, but I would like to hear how you do it in your team and any interesting thoughts down the line.
Why on-call wasn’t a thing for data engineers?
On-call can be stressful. When a production issue kicks in, engineers immediately get paged inside or outside of regular working hours and do their best to do the first steps of incident management. They are aware that anxious customer are eagerly waiting for service to be restored. They understand that a prolonged delay in fixing the issue would result in the loss of customers and revenue for the company.
However, many data engineers believe that pipeline issues have limited impact on customer satisfaction and revenue, leading to a lack of incentive to be on standby at all times. This perception may stem from the fact that much of the data is used by data analysts and scientists to create dashboards and reports which are not directly customer-facing and may not require immediate attention.
Another reason is that many data issues are turned into feature requests. The “bug or feature” discussion is a common occurrence in the data domain. This can be particularly problematic for data teams that haven’t defined any SLA or SLO with their users, as issues caused by lack of requirements are categorized as new features, leading to lower prioritization. In principle, on-call aims to resolve urgent issues rather than handle feature requests.
Moreover, the complicity of the data flow, coupled with users’ misinterpretation of metrics, and unforeseen variables in the source data, can contribute to feelings of frustration.
It is the case that data engineers face different types of production issues than software engineers. So the voice in our mind might be “Hey, sounds like data engineers don’t need an on-call process. Lucky them.”
What do data engineers do during on-call?
In my opinion, on-call is not only about solving the most urgent production issues swiftly, but it is also about standardizing the process to handle unexpected production requests. For data engineers, this is particularly important because they are confronted with much more diverse issues compared to software engineers.
If you consider creating an on-call culture, it’s a good exercise to list all the production issues and requests the team receives that are outside of their daily scope, and give each a description and priority. Here is an example:
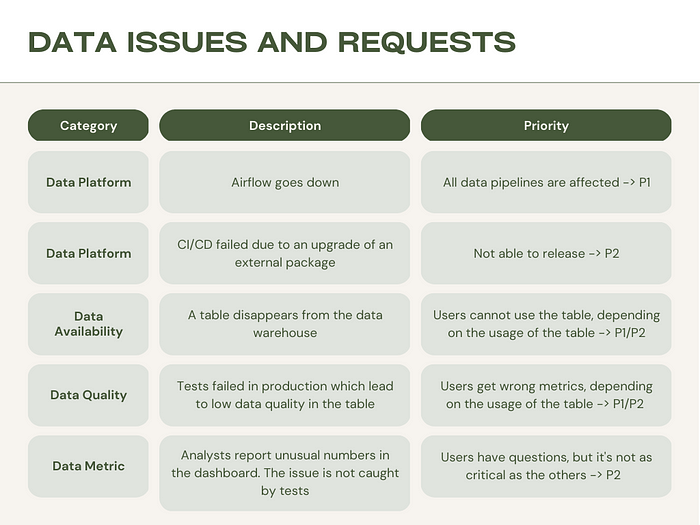
Eventually, someone from the team should process the requests following a guideline. The more detailed the guideline, the more streamlined the on-call process will be. It’s essential to establish a fair environment for everybody to get involved in the on-call process. In this respect, it doesn’t sound so different from software engineers, right?
Next, I will share some tools and frameworks to establish the on-call culture. Keep in mind that there is no one-size-fits-all approach and you don’t need to use all the tools. Pick up the tools that make more sense for your team.
On-call workflow
The key to building a healthy on-call culture is proper preparation. More preparation means fewer decisions we have to make on the spot, leading to fewer mistakes. On-call workflow tells engineers how to approach a variety of production requests in a consistent manner.
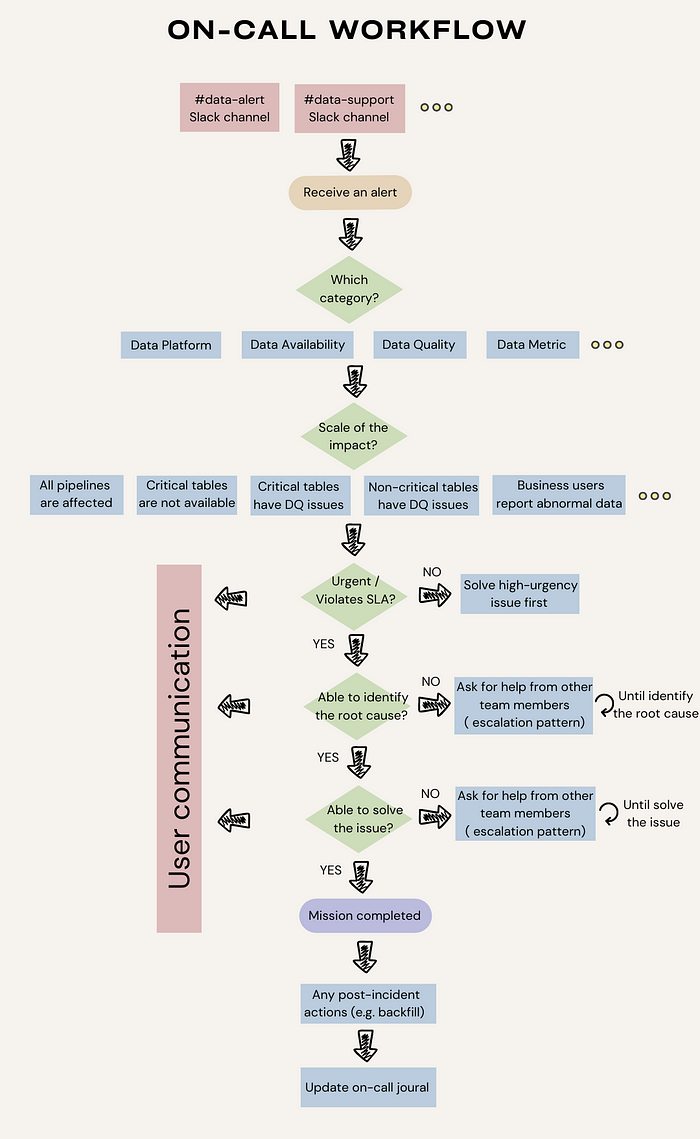
The above workflow is a template and you should adjust it according to your needs, but here are the main steps:
- Define the sources of alerts. Redirect all production issues into one or two channels. For example, use Slack integration to redirect pipeline issues, infrastructure failures, and test failures into a centralized Slack channel for easy tracking.
- Identify the category of alerts, the scale of the impact, and its urgency. Every on-call should be able to assess the urgency of the issue based on its category, impact, and SLA requirements. By creating “data products” with clear requirements, teams can benefit from the process that enables them to identify the impact and urgency efficiently. I recommend article — Writing data product pipelines with Airflow, a nice practice to write data requirements as code in Airflow dags.
- Identify the root cause and solve the issue. When an urgent issue arises, on-call should do their best to find the root cause and solve the issue. However, not every data engineer knows all the nitty-gritty of data models maintained by data analysts. In such situations, following an escalation pattern can be helpful. It allows engineers to ask for help from other engineers or analysts with necessary expertise until the issue is resolved.
- Perform post-incident actions and update the on-call journal. Don’t forget to perform post-incident actions like backfilling to correct historical data for incremental models. It’s also recommended to keep an on-call journal for knowledge sharing.
- User communication. In a parallel thread, it’s important to keep users in the loop. Effective communication during the “data downtime” builds trust between the data team and users. One of my articles — Status Page for Data Products — We All Need One introduces the status page as a method to improve effective communications during data downtime.
On-call ownership
As reported in State of Analytics Engineering 2023 from dbt, the top data challenge for all data practitioners is ambiguous data ownership. This challenge also leads to the question during on-call “who should fix the issue?”
I guess the answer is “it depends”.
The on-call ownership very much depends on the day-to-day job of data engineers. Clearly, engineers are responsible for technical failures, but when it comes to data model failure, ownership becomes controversial. Whether it’s a centralized or decentralized data team, data engineers always need analysts’ wisdom to diagnose and resolve model-related issues. In the end, it creates shared ownership. In my humble opinion, two approaches may help the collaboration:
- Assign an owner to each data model as much as you can. Simply assigning an owner to the model tremendously improves efficiency during on-call.
- Treat data model owners as “external parties”. It’s not uncommon that software relies on an external party that is outside of engineers’ control such as an IoT service that relies on a network provider. Similarly, data engineers may need to work with model owners who are outside of their immediate team to address the model failures. When external knowledge is required, engineers should feel comfortable reaching out and proactively working with them while informing users of the progress. Do not put stress on on-call engineers by expecting them to solve issues on their own.
Tools 1 — On-call rotation
To get you started, here are a few tools to streamline the process and help engineers focus on what really matters.
Schedule
On-call rotation is a schedule to rotate a group of on-call engineers, ensuring that there is always an on-call person each week. This sets expectations for engineers regarding time, colleagues, and scope.
A free setup is to use spreadsheets to manage rotation schedules and a cron job to propagate the schedule into a calendar in near real-time. An example is Google Sheets + Apps Script + Google Calendar. Some teams prefer to use paid software like Opsgenie and PagerDuty. They save time and minimize manual overhead, but it comes with a cost.
Permission
On-call engineers occasionally need additional permissions to resolve production issues. One approach is to perform a permission escalation, temporarily granting the engineer additional privileges. Another option is to create a high-privileged user group and rotate group members. It’s essential to ensure that the rotation of the group members must be in sync with the on-call calendar rotation.
Tools 2 — Communication channels
Effective communication is key during data downtime. The on-call process involves several layers of communication, and finding the right balance between being informed and not being overwhelmed by alerts is crucial.

Centralized data alerts channel (alerts -> team)
By having a dedicated channel where all alerts are sent, it becomes easier to monitor and manage alerts, reducing the risk of critical information being missed or overlooked. Slack is a popular choice because it can easily integrate with various data sources such as Opsgenie, GCP Cloud logging, Sentry, service desk, etc. It allows on-call to quickly respond to the issue and enhances collaboration with other engineers.
Escalation policies (team -> team)
Escalation policy is a set of procedures that outlines how an organization will respond to issues that require additional resources beyond the initial response. When the first tier of defense couldn't solve the issue within a certain time, the second tier should be informed timely.
Most incident management tools allow the team to define escalation policies, and the tool will automatically route notifications to the right expert at the right time. If the model ownership is properly defined, the tool can automatically alert the owner by reading the model metadata.
User communication (team -> users)
The last layer is user communication which needs to start as soon as the issue is identified. Keeping the channel centralized by setting up a tool like status page.
Tools 3 — On-call runbook
On-call runbook is a set of instructions that on-call can follow when responding to issues. A data pipeline runbook typically includes:
- Metadata around the data product: owner, model incrementality, priority, schedule, SLA, and SLO.
- Escalation procedures (if not handled automatically).
- Troubleshooting guides: how to solve common issues. For example, perform full-refresh, check source data, logs, data observability tools and etc.
- Post-incident verification: how to verify if the issue is properly solved. For a cron job, the issue can only be verified in the next run which can be a few hours or days later.
On-call runbook is a live documentation that must be regularly updated to reflect the changes. Again, I really like the idea of article Writing data product pipelines with Airflow where the author writes requirements as code in Airflow dags. This is a good example of linking documentation and code, ensuring that the documentation is always up-to-date and relevant.
Tools 4— On-call journal
On-call journal is a tool for documenting production issues. It helps engineers who look for tested solutions and managers who search for trends. A templated journal ensures engineers approached each issue with the same scientific rigor. Each record includes intensive metadata around the issues and the in-depth investigation and what they did to fix the issue. With the mindset of “focusing on the issue, not people”, engineers are comfortable with sharing more details.
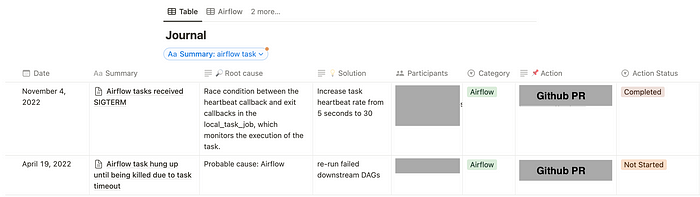
On-call can serve as a mirror that reflects the maturity of the team. It’s normal for a young team to experience some chaos during on-call at the beginning. However, these challenges can push team to improve their monitoring, automation, documentation and requirement gathering process. Ultimately, on-call can be a valuable learning experience for everyone on the team.
Conclusion
For people who are new to on-call, this article provides valuable insights and expectations for what to expect. For data leaders looking to establish an on-call culture, you have a bunch of toolboxes to work with. Begin by creating the workflow and gradually fill each step with the correct tool. In the end, on-call is more of a cultural challenge than a technical one. With the right mindset and tools in place, on-call can become a valuable opportunity for personal growth as well as company growth. Cheers!



{kind=link}